Data Engineer, TX, Health-Chain (Nov 2023 - Present)
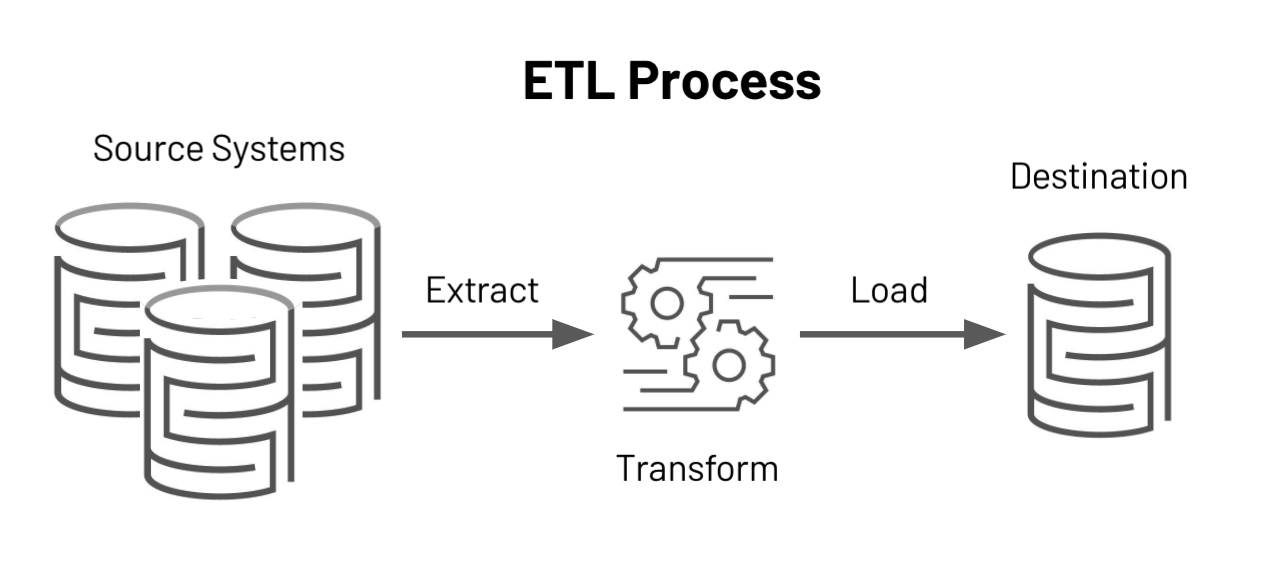
Associated with a startup, collaborating with cross-functional teams to design an end-to-end ETL pipeline for a healthcare data analysis solution utilizing the HL7 FHIR server.
- Boosted upstream data ingestion from FHIR API by 25% using Azure Function App with a timer trigger.
- Reduced code integration errors by 20% by implementing GitLab version control for CI/CD pipelines
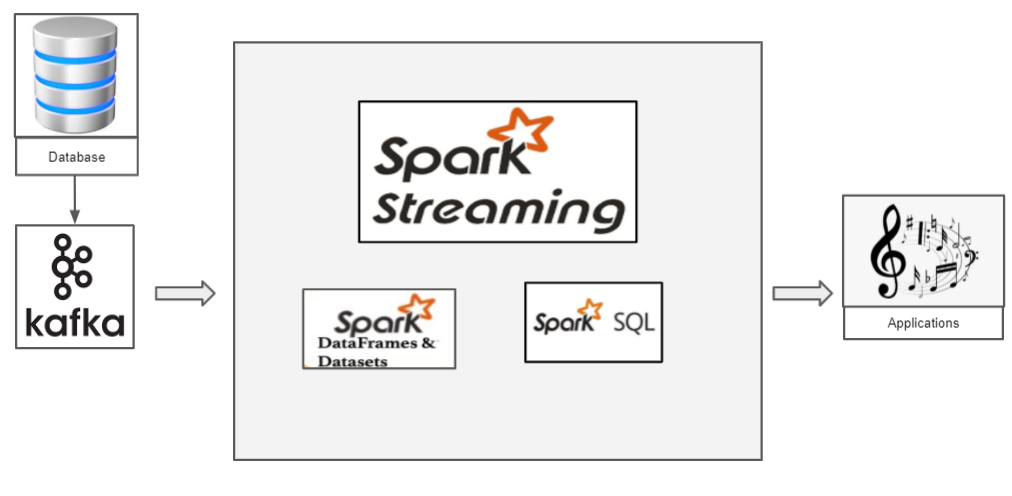
- Transformed 1 million patient records using Spark DataFrame API for analyzing patient authorization data.
- Established data integration connections with APIs and cloud services.
Associated with a startup, collaborating with cross-functional teams to design an end-to-end ETL pipeline for a healthcare data analysis solution utilizing the HL7 FHIR server.
 R
R
 AWS DynamoDB
AWS DynamoDB
 Apache Kafka
Apache Kafka
 Apache Airflow
Apache Airflow
 Hadoop
Hadoop
 AWS
AWS
 Azure
Azure